Insights into Evolution: Machine Learning Reveals Clues to our Complex Ancestry
When people think of evolution, fossils, and the deep past, such charismatic fauna as dinosaurs, mammoths, and saber-toothed cats are what often come to mind. While these are some of the most famous characters in paleontology, the study of our own evolutionary heritage is among the most heated topics in the field. This past month a team consisting of Colin Brand, Laura Colbran, and John Capra published their findings of genetic mechanisms in recent human evolution in the journal Nature, Ecology, & Evolution. A complex intersection of paleontology, genomics, and computational biology, their work explores alternative splicing in the genomes of recent human relatives.
The Genus Homo
Humans and our closest relatives fall within the genus Homo, with humans having the full taxonomic name of Homo sapiens. While our species has only been around for several hundred thousand years, earlier members of the genus such as Homo erectus lived several million years ago. The evolution of our genus and the various distinct species that have arisen within it have been a subject of great interest within the field of paleoanthropology. While research involving many of the more ancient species has been largely reliant on fossils evidence due to the natural breakdown of DNA, remains of some of our recent relatives often contain samples of DNA. This informative molecule can be extracted from the remains through various procedures and used to gain considerable insight on the lives and appearance of ancient human relatives. Brand’s team used the remains of two distinct human ancestors, the Neanderthals and Denisovans, to acquire genetic data for their exploration of alternative splicing.

An artist’s reconstruction of a Neanderthal equipped with a stone tool. Image credit: Chuang Zhao
Neanderthals are likely among the famous human relatives. Traditionally depicted as brutish and unintelligent, recent studies have found that Neanderthals are among our closest relatives and likely shared social and cultural characteristics with humans. Neanderthals were once common in Europe and the Middle East during the late Pleistocene (colloquially termed the Ice Age) and evidence has shown that they interbred with early humans. The second group of hominid, the Denisovans, are an enigmatic group of human relatives that are known only from scant fossil remains. Remains of Denisovans - consisting of teeth and a few other elements - were first identified in Denisova cave in Siberia. Recent interest in Denisovans and the successful extraction of DNA from their remains have allowed us to learn a considerable amount about their lives and their potential relationship with Neanderthals and humans. Further discoveries of remains on the Tibetan plateau and nearby areas have advanced our understanding of these poorly known hominids. Brand et al. (2023) used published DNA sequences from one Denisovan and three distinct Neanderthal specimens to uncover a key mechanism behind the evolutionary divergence of late Homo.
The Biology: An Overview of Transcription and Translation
DNA is commonly referred to as the “key to life” and is instrumental to a large body of biological research, but what exactly can be learned from this molecule? Brand’s team used the genetic information from the Neanderthal’s and Denisovans to investigate a mechanism known as alternative splicing, but to understand this concept one must have a basic concept of the function of DNA. The central dogma of biology, doubtless a familiar term to any biology student, is that DNA produces RNA which produces proteins essential to cellular functions. As the dogma implies, the process of protein production begins at DNA, the “instruction manual of the cell”, which consists of the nucleotide bases adenine (A), guanine (G), cytosine (C), and thymine (T).
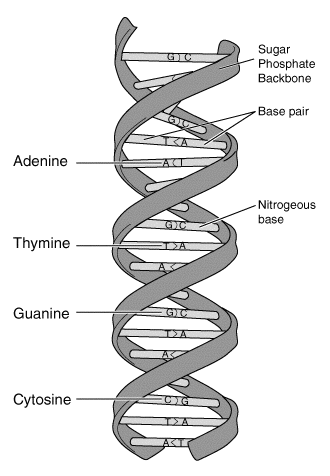
A schematic of the basic structure of a DNA molecule. Image credit: Talking Glossary of Genetics.
The nucleotide bases pair with one another according to base pairing rules, forming the characteristic double helix structure of DNA. The specific order of nucleotide bases provides the basic instructions that are carried through the protein production process to produce essential proteins.
The first step of the protein production process is known as transcription, and, as the name implies, it involves the synthesis of a copy of the instructions contained by the DNA. Transcription occurs when a specialized enzyme breaks the bonds holding the complementary nucleotides together causing a small section of DNA to unravel. A second enzymatic complex attaches itself to a specific section of DNA known as the promoter sequence and takes free nitrogenous bases from the surrounding environment and pairs them with one strand of the unfurled DNA. As the nitrogenous bases are paired with the DNA strand, a single-stranded entity known as messenger ribonucleic acid (mRNA) is created. The enzymatic complex responsible for RNA synthesis continues to attach base pairs to the DNA strand (transcribing) until it reaches a section of DNA where transcription ends. The full section of DNA following the promoter sequence and preceding the terminating sequence that is transcribed in the mRNA is known as a gene and it provides instructions for the formation of a specific protein.
A diagram of the transcription process in which RNA is synthesized from DNA. Enzymes unravel a segment of DNA to create a transcription bubbles as shown, and the second enzymatic complex (RNA polymerase) synthesizes mRNA (the RNA transcript). The U represents uracil, a nucleotide base that replaces thymine in RNA. Image credit: Adobe stock photos.
When mRNA synthesis has been completed, it undergoes several modifications before reaching the final iteration of mRNA. The process of transcription occurs in the nucleus of the cell where DNA is housed, and the modified mRNA is exported from the nucleus to the cell’s cytoplasm. Once it reaches the cytoplasm, the second phase of protein synthesis, translation, takes place. As the modified mRNA leaves the nucleus, it attaches to a specialized complex of RNA and proteins known as a ribosome. The ribosome is divided into two parts, the small subunit and the large subunit, with the mRNA initially attaching itself to the small subunit. Following this attachment, the large subunit attaches itself to the mRNA, and the ribosomal complex is ready for protein synthesis.
Amino acids, the most basic building blocks of proteins, are carried to the ribosomal complex by entities known as transfer RNA (tRNA). tRNA, which are synthesized in the nucleus, are designed to bond with only a select amino acid. When it has bonded to this amino acid, the tRNA travels to the ribosomal complex. The tRNA contains a 3-nucleotide sequence known as an anti-codon that pairs with 3 nucleotides on the mRNA (known as a codon) that code for the specific amino acid bonded to that tRNA. The tRNA initially binds to the mRNA at a location known as the P site, though it is later shifted over as the mRNA moves like a conveyor belt and more tRNAs bind to codons as they pass through the P site. The amino acids located at the end of the tRNAs form peptide bonds with one another and eventually form a complete polypeptide once a stop codon reaches the P site. The polypeptide produced at the end of the translation process undergoes several modifications and becomes a protein that serves an essential function within the cell.
The transcription and translation process shown in a complete diagram. At the bottom half of the diagram the ribosome can be seen with a growing polypeptide exiting the large subunit. Image credit: Nature Education.
Alternative Splicing
Having established an understanding of transcription, translation, and the process of protein synthesis, one can now explore the idea of alternative splicing. Following transcription, the newly produced mRNA undergoes several modifications to prepare it for polypeptide synthesis through translation. A key step in modification is RNA splicing, which involves the removal of segments of RNA that are not involved in coding for the desired polypeptide. These non-coding segments are known as introns while the remaining coding segments are known as exons. An enzymatic complex known as a spliceosome assists in the removal of introns and binds adjacent exons to form the final mRNA.

A schematic showing the basic process of RNA splicing. Image credit: GEP Flickr.
The process of RNA splicing, however, is not always seamless. Alternative splicing refers to the potential of creating numerous different polypeptides from a single gene depending on which segments of RNA are removed during RNA splicing. The production of various polypeptides can be due to errors in the splicing process or simply natural variation. Changes in RNA splicing over time can lead to the synthesis of a large number of polypeptides that differ significantly from those that were originally produced. These polypeptides go on to make new proteins that can alter cellular functions and at times cause phenotypic differences in behavior and morphology. Alternative splicing and variation in the production of proteins has been explored as an agent of speciation and has been observed to undergo rapid evolution in certain instances. Brand’s team used the DNA sequences of the Neanderthals and the Denisovan to identify genetic sequences that were affected by alternative splicing and the differences observed in the polypeptides that were synthesized.
The Findings
The published Neanderthal and Denisovan genomes were analyzed with the neural network SpliceAI to estimate probabilities and locations of potential alternative splicing using only sequenced DNA. The network identified splice-altering variants (SAVs) in each of the genomes and compared them. Furthermore, the SAVs were compared to those present in modern human genomes as a metric of shared ancestry. Computational analysis was performed on the SAVs identified in each hominin genome to predict the protein variants that could be generated from each affected gene and what impact the production of each variant would have on the appearance, or phenotype, of the individual.
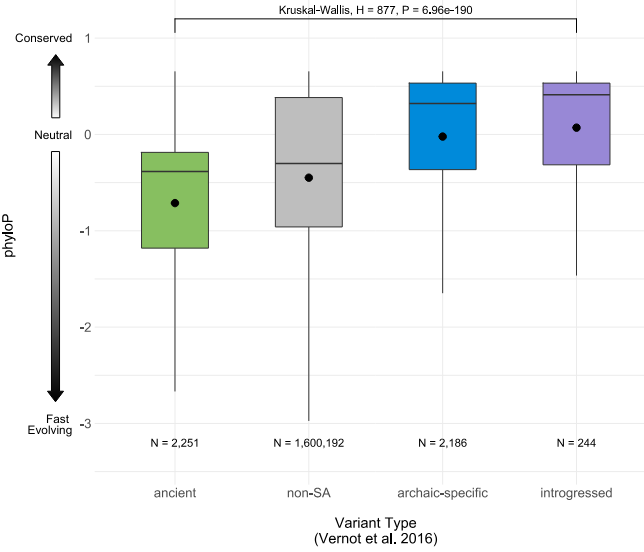
A boxplot comparing the phyloP scores (a measure of genetic changes over time) of three types of SAVs identified along with non-SAV sequences. Image credit: Brand et al., 2023.
With the assistance of SpliceAI, the researchers found over one thousand SAVs among the Neanderthal and Denisovan sequences. Comparing these sequences and identified SAVs to modern human genomes, they found that a large number of SAVs were not found in modern humans. The authors speculated that some of these SAVs and the different proteins produced may be responsible for phenotypic differences observed among humans, Neanderthals, and Denisovans. Even so, many SAVs, termed archaic SAVs, were found to be present in modern human genomes. These may contribute to physical differences among human populations today. The authors specifically identified that a decrease in the production of the EPAS1 gene held in common by the Denisovan genome and modern Tibetan genomes may be correlated with increased resistance to low oxygen at higher altitudes.
The successful combination of machine learning to derive more complex information from ancient genomes opens up a new avenue in scientific analysis of evolution and ancient life. Brand’s team hope that similar techniques will continue to be used to provide further context on the recent evolution of Homo and other extinct organisms. To view the full details of the study, view the publication on Nature.