Clues to Cancer: Predicting Colorectal Cancer Through Oxidative Stress
When asked of the greatest challenges that face humankind, one is likely to hear of nuclear war, global warming, pandemics, and cancer. The latter is among the most pressing issues in clinical research today, affecting millions of people worldwide. Although cancer is often generalized as a type of disease, there is high diversity among cancers and they often arise in different ways. The inherent diversity of cancers makes them extremely challenging to detect and treat, and oftentimes a prognosis (predicted outcome of the individual when given treatment) lacks high accuracy. A vast body of scientific research has targeted cancer, with clinical scientists searching for ways to improve our understanding of this malignant affliction for better detection, prognosis, and treatment options. With the development of advanced artificial intelligence and powerful computer systems, numerous predictive algorithms have been engineered to better detect cancer and predict its long-term outcome. Rui Chen and Jun-Min Wei, researchers at the Department of Oncology of Cheeloo College of Medicine, have developed such an algorithm to produce a deeper understanding of colorectal cancer.
Machine Learning and Cancer Diagnosis
Any even slightly familiar with cancer know how difficult it can be to treat and dread the real possibility of a poor prognosis. Research over the past few decades has capitalized on the development of advanced new technology to greatly improve cancer treatments and diagnostic methods. However, many existing treatments face challenges in exclusively targeting malignant cells and can lead to the death of perfectly healthy cells. While novel treatments are being discovered and medications are being refined to better target cancerous cells, avoiding aggressive treatment options remains the optimal route.

A microscope image of malignant tumor cells. The irregular shape of the cells is characteristic of cancerous bodies. Image credit: Beckman Coulter.
Early diagnosis and regular screenings for common types of cancer are practices that can often lead to a positive prognosis. Current imaging technologies allow for visualization of target areas using non-invasive procedures and can provide clear images to medical professionals for observation. While imaging technology has advanced sufficiently for proper diagnosis, it alone cannot identify cancerous tumors or other features that may be indicative of cancer. Typically, medical professionals perform this task, but a limited number of professionals and a large amount of data can pose a problem along with human error involved in diagnoses. As such, there has been growing interest in developing software programs capable of detecting features characteristic of cancer with equal or higher accuracy than human professionals.
Machine learning, the primary field of computer science applied to this issue, is a subfield of artificial intelligence that uses statistical algorithms to make predictions. Generally, a predictive algorithm is generated and it is fed a raw dataset known as a ‘training set’. In the case of cancer diagnosis, the training set might be a large database of images with the cancerous feature marked by a medical professional. The algorithm uses the dataset to ‘learn’ how to identify cancerous features and is able to apply this newfound knowledge to find similar features in images it has not encountered before. Although modern machine learning has certain limitations, the explosion in artificial intelligence research has allowed for the emergence of highly accurate algorithms that can be used for clinical and scientific applications. In the case of cancer prevention and diagnosis, researchers hope that future machine learning algorithms can better predict the presence of cancer. Chen and Wei are among the researchers exploring this field, and have aimed to train a machine learning algorithm to predict the progression and long-term outcome of colorectal cancer using oxidative stress.
The Biology: Oxidative Stress
Many readers are likely familiar with the extensive supplements section in any grocery store or pharmacy. Supplements are often touted to boost health and productivity, and many are labeled as healthy ‘antioxidants’. Have you ever wondered what the term antioxidants truly referred to?
Antioxidants are compounds that, as the name implies, are used by cells to prevent oxidation. In this case, oxidation would be caused by a process known as oxidative stress. In general terms, oxidative stress is a condition in which a cell is unable to control toxic compounds generated through natural metabolic activities. Oxidative stress is caused by peroxides, a group of compounds consisting of oxygens and charged atoms, and free radicals, ions that are highly reactive due to their possession of free valence electrons. The high reactivity of peroxides and free radicals makes them toxic to cells as they readily bind to atoms contained within key cellular structures. Interactions between constituent atoms and these compounds can lead to the destruction of proteins, lipids, and even DNA. To counteract the damage caused by peroxides and free radicals, cells contain natural defenses that often involve proteins and catalysts. These defenses detoxify damaging compounds to minimize the damage caused to cellular structure.

A Lewis structure of superoxide, a common free radical produced within cells. Superoxide is negatively charged, which, paired with the high electronegativity of oxygen, makes it highly reactive.
Considering the toxicity of free radicals and peroxides, why are they produced at all? As mentioned before, these compounds are natural products of essential metabolic processes and can often result from slight errors in said processes. Among the most famous examples of free radical production is mitochondrial generation of adenosine triphosphate. The mitochondria, specially designed organelles that are present in all eukaryotic cells, are responsible for generating large quantities of the molecule adenosine triphosphate (ATP). Due to the negative charge of phosphate groups and the natural repulsion between phosphate groups bonded to one another, ATP contains a large amount of stored energy that can be exploited to power cellular processes.
ATP is generated within mitochondria in three distinct steps. The final step, oxidative phosphorylation, is generally where free radicals such as superoxide are produced. When the stage of oxidative phosphorylation is reached, two different coenzymes (compounds that assist with metabolic processes) have been reduced through the acquisition of electrons. The two reduced coenzymes, NADH and FADH2, are used to power a system known as the electron transport chain.
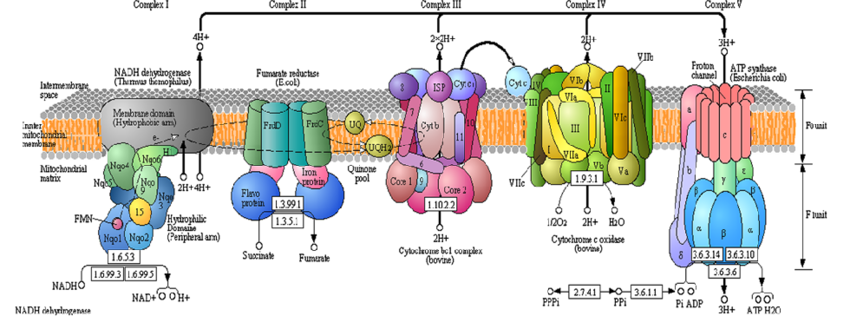
A complex diagram showing the different proteins involved in the electron transport chain. The bottom of Complex V shows the processes where water - and free radicals - are generated. Image credit: (Korla & Mishra, 2013).
As with other biological entities, the structure of mitochondria is perfectly suited to its specific function within the cell. The mitochondria contains two membranes, and inner membrane and an outer membrane, and a fluid-filled space between the membranes known as the intermembrane space. This layout of membranes is critical to the function of the electron transport chain, a series of proteins that use energy from electrons to pump hydrogen ions (H+) from within the mitochondria to the intermembrane space. When the reduced coenzymes NADH and FADH2 reach the inner mitochondrial membrane, their additional electron is removed by the first enzymatic complex in the electron transport chain. The coenzymes, having been restored to their initial state, can be used once again in the previous steps of ATP production. The electrons taken by the first complex are used to power the movement of H+ against the concentration gradient into the intermembrane space. The electrons, having decreased energy, move to the next enzymatic complex in the chain and are once again used to pump H+ into the intermembrane space. This process continues and the electron loses energy as it moves from complex to complex and H+ is continually pumped across the inner mitochondrial membrane. Due to the high concentration of H+ within the intermembrane space, it is acted on by the powers of diffusion and attempts to move back across the membrane to a less concentrated environment. H+ cannot traverse the membrane of its own accord, but is forced to move through an enzymatic complex known as ATP synthase. As the name implies, ATP synthase synthesizes ATP. The energy produced by H+ moving through ATP synthase is used to generate ATP.

A simplified diagram of the enzymatic complex ATP synthase. When H+ ions flow through the complex, they power a mechanical motion that produces energy used for ATP synthesis. Image credit: Max Planck Institute of Biophysics.
While ATP production, the end goal of oxidative phosphorylation, is accomplished via ATP synthase, what happens to the electrons? At the end of the electron transport chain, the electrons have lost sufficient energy to become low energy electrons. Low energy electrons are of little use to the mitochondria since they cannot be used to pump H+ across the membrane. However, there are certain highly electronegative atoms that would be glad to receive low energy electrons. Oxygen, supplied by the body’s respiratory and circulatory systems, is highly electronegative and serves as an ideal electron acceptor. When oxygen receives the electrons, it bonds to free hydrogen atoms within the mitochondria to generate water as a waste product. Water, being harmless to the cell, is a benign waste product, but water is not always produced. Certain imbalances within the mitochondria or issues affecting its mechanisms can hinder the production of water and lead to the formation of free radical instead. One of these free radicals, superoxide, consists of a diatomic oxygen with an additional valence electron. These free radicals can leak out of the mitochondria and be released throughout the cell, damaging any cellular components that interact with them.
Mitochondria are among the most common examples of free radical production, but other cellular processes also produce free radicals and peroxides. As natural byproducts, their production cannot be stopped and cellular defense mechanisms are required to keep them in balance. When a cell is in oxidative stress, it cannot regulate the quantity of free radicals contained within and proteins, lipids, and DNA can face extensive damage. If oxidative stress reaches critical levels, cells can face sufficient damage to undergo apoptosis, a form of programmed cell death. When a cell undergoes apoptosis, it releases lytic enzymes and other compounds that degrade the plasma membrane and release the contents of the cell into the environment.

A diagram detailing the process of apoptosis. High levels of oxidative stress can impair a cell’s ability to perform basic metabolic functions, leading to apoptosis. Image credit: National Human Genome Research Institute.
Apoptosis can occur in more extreme cases of oxidative stress, but oftentimes cells continue to function and can sustain considerable damage. Damage to proteins, lipids, and DNA caused by interactions between these molecules and free radicals has been linked to numerous human diseases. Among these diseases are Alzheimer’s disease, cardiovascular disease, sickle cell disease, atherosclerosis, and cancer. In cancer specifically, free radicals responsible for oxidative stress can cause harmful mutations by interacting with DNA. These mutations can generate malformed cells that divide rapidly and do not undergo programmed cell death. These new malignant, or cancerous, cells form tumors and often spread throughout the body from the source cell. The connection between oxidative stress and cancers makes signs of oxidative stress a possible method for diagnosing cancer and predicting its progression. Chen and Wei targeted long noncoding RNAs (lncRNAs), strands of RNA that play a role in regulating oxidative stress, as they constructed their machine learning algorithm.
The Findings
To create the algorithm for prediction and prognosis, the team identified a dataset that would provide useful insight into the connection between oxidative stress and colorectal cancer. They began by finding differentially expressed oxidative stress-related genes (DEOSGs) and determined their function and drug response using the software programs Kyoto Encyclopedia of Genes and Genomes (KEGG) and Gene Ontology (GO) (For further information on these programs and their role in computational biology, visit Chapter 1 of the Course). With these genes identified, the researchers used an online database of lncRNAs and related mRNAs to train a machine learning algorithm that they had designed. The algorithm employed several statistical methods to analyze the lncRNAs and associated mRNAs to predict the progression of colorectal cancer and the expected result of treatment.

A boxplot showing the distribution of tumor mutation burden (number of mutations per hundred base pairs of DNA in cancer cells) for low risk and high risk patients. Image credit: (Chen & Wei, 2023).
Through analysis of the cancer data and the creation of the machine learning model, the team identified 9 specific lncRNAs that were related to oxidative stress. They determined that individuals that had higher rates of expression of any of these lncRNAs obtained a better prognosis. Following testing of the machine learning algorithm, the researchers were able to generate a predicted curve for patient prognosis with relatively high accuracy. However, they noted that there were several limitations to their study and that these would have to be taken into account to eliminate any possible biases and establish a more solid foundation for their algorithm. The authors hope that continued explorations into machine learning, oxidative stress, and colorectal cancer will better our ability to treat this condition through more accurate predictions of its progression and the long-term outlook for patients. To learn more, read the open access paper published in BMC Bioinformatics.